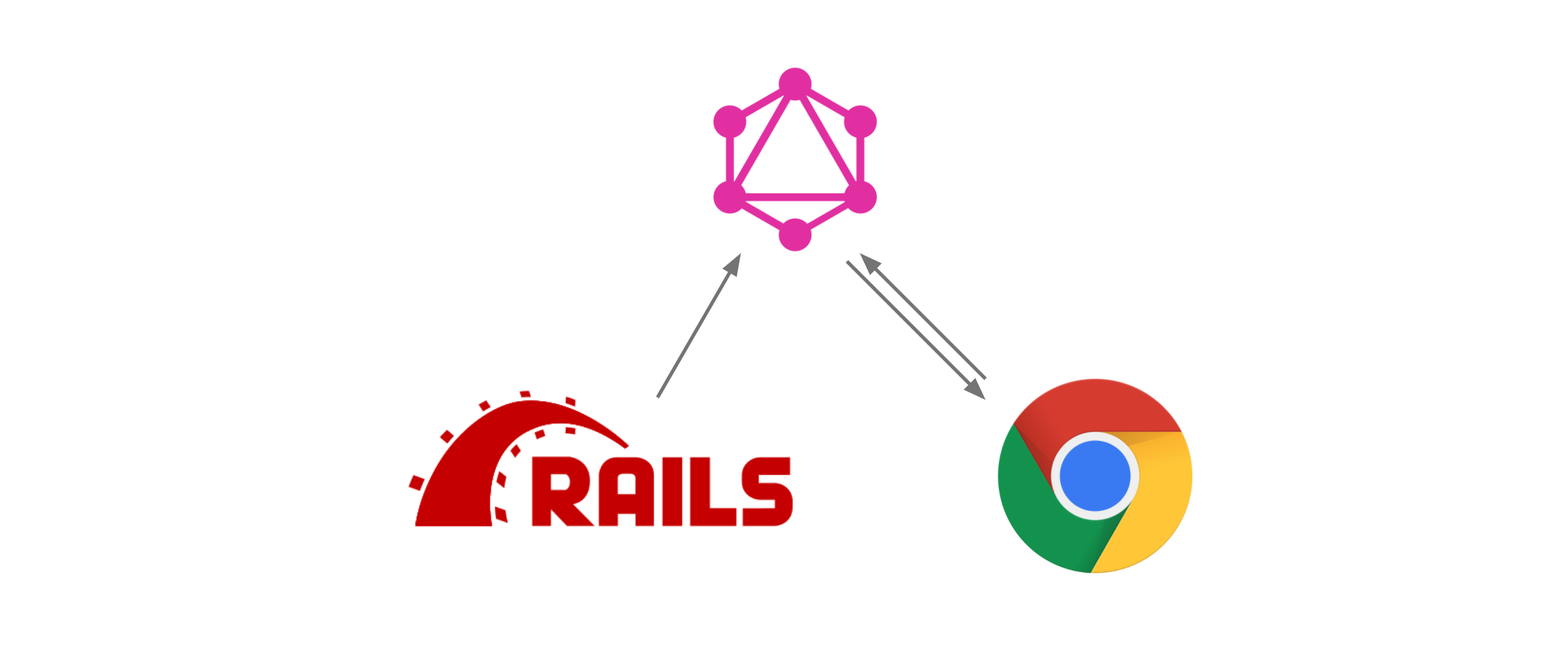
This article—adapted from a talk I gave at GraphQL Conf. 2021—describes how Salsify's GraphQL environment creates a productive, enjoyable, and cohesive developer experience from the backend to the frontend.

This article—adapted from a talk I gave at GraphQL Conf. 2021—describes how Salsify's GraphQL environment creates a productive, enjoyable, and cohesive developer experience from the backend to the frontend.
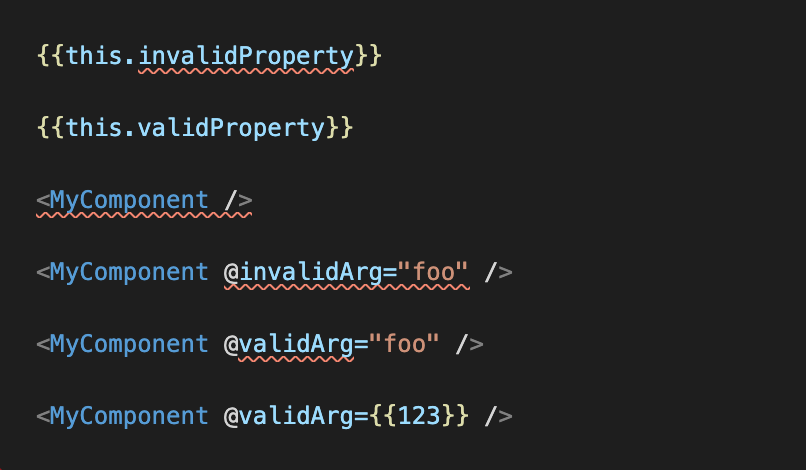
Glint
TL;DR?
glintrc.yml file in the root of your app or addon containing:environment: ember-loose@glint/environment-ember-loose/glimmer-component in place of @glimmer/component.
We recently decoupled our platform's search functionality from our main application. The search functionality required deep knowledge of some specialized systems (like Elasticsearch), was inaccessible to other services that wanted to offer text search and had much different throughput requirements than the rest of the application.
Or: How I Learned to Stop Worrying and Love __typename

This articles describes the difference between how component invocation differs when using curlies {{...}}, angle brackets <...> or an (...) s-expression in Ember templates.

The GraphQL website describes the tech as "a query language for APIs and a runtime for fulfilling those queries with your existing data." But what does this mean in practice? When am I actually supposed to use GraphQL, and why?

A challenge often faced in multi-tenant SaaS is ensuring that each tenant gets a fair share of a platform's resources. At Salsify, we had to address this in our Delayed Job-based background task execution infrastructure. Because our customers have different use cases, they tend to run tasks of varying complexity and size. Over time we developed tenant-fairness job reservation strategies that made scaling our job system difficult if not impossible. In this post, I discuss how we managed to extend Delayed Job to solve for tenant fairness in a scalable manner.

2019 has been a great year for Ember so far, so while my peers are focused on setting direction for the framework for the rest of 2019, I wanted to take stock of the existing addons ecosystem.


I'm writing this near the end of the official #EmberJS2019 window, which means a lot of what there is to say has already been said. As I've read through this year's posts, there are a handful of themes I see coming up over and over again:
These points are each important and valuable in their own right, and I'm hopeful that the 2019 Roadmap RFC will address all of them. Many of the posts discussing them, though, brush up against something that I think merits a more explicit discussion.
Over the past couple years I've seen an increasing number of Ember folks display a mentality that divides the world into Us and Them. It manifests in social media interactions and blog posts, day-to-day chatter in the Ember Discord server, and even the way we frame meetup and conference talks. I think it's driven by a desire to see Ember succeed and to convince other people that they should like this thing as much as we do, but it ultimately does everyone involved a disservice.