

A challenge often faced in multi-tenant SaaS is ensuring that each tenant gets a fair share of a platform's resources. At Salsify, we had to address this in our Delayed Job-based background task execution infrastructure. Because our customers have different use cases, they tend to run tasks of varying complexity and size. Over time we developed tenant-fairness job reservation strategies that made scaling our job system difficult if not impossible. In this post, I discuss how we managed to extend Delayed Job to solve for tenant fairness in a scalable manner.
Delayed Job At Salsify
Delayed Job at its core is comprised of jobs, queues, and workers. Jobs contain the business logic you would like to run and are written to a database table when application code enqueues jobs. Queues function as a stream from which workers reserve and run jobs. Workers are responsible for managing the job lifecycle and ensuring that jobs are run within their respective environment correctly. Our core repository service used Delayed Job in this configuration; running 100 workers from a Postgres database. 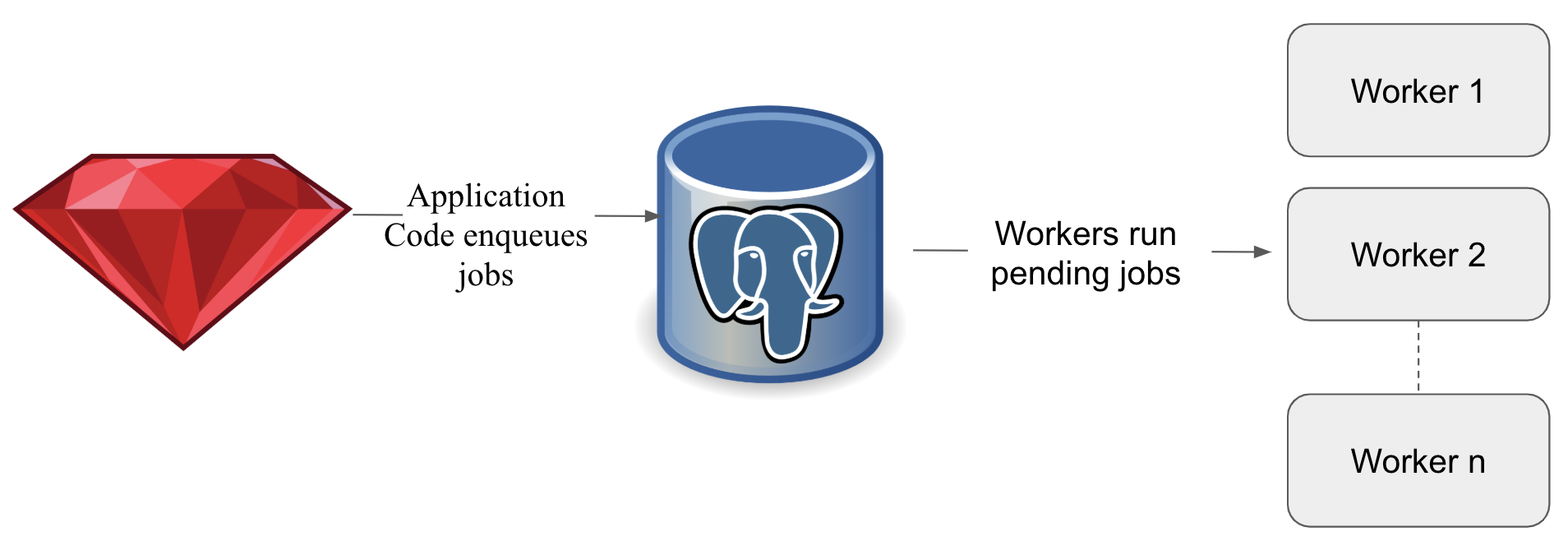
Simplified Representation of Delayed Job
Our Earlier Solutions
One of the simplest strategies a worker can use to reserve jobs is FIFO ordering which can be achieved by having the database order pending jobs by insertion order. Unfortunately, in a multi-tenant environment, high usage tenants can easily lock up all available workers by enqueuing large numbers of jobs in short succession. For example, assuming we are running two workers and have two tenants (Jane and Jon). If Jane were to enqueue 2 or more jobs right before Jon, Jon would be effectively locked out from processing any background tasks until all of Jane’s tasks completed. Jon would be understandably very upset by his user experience.
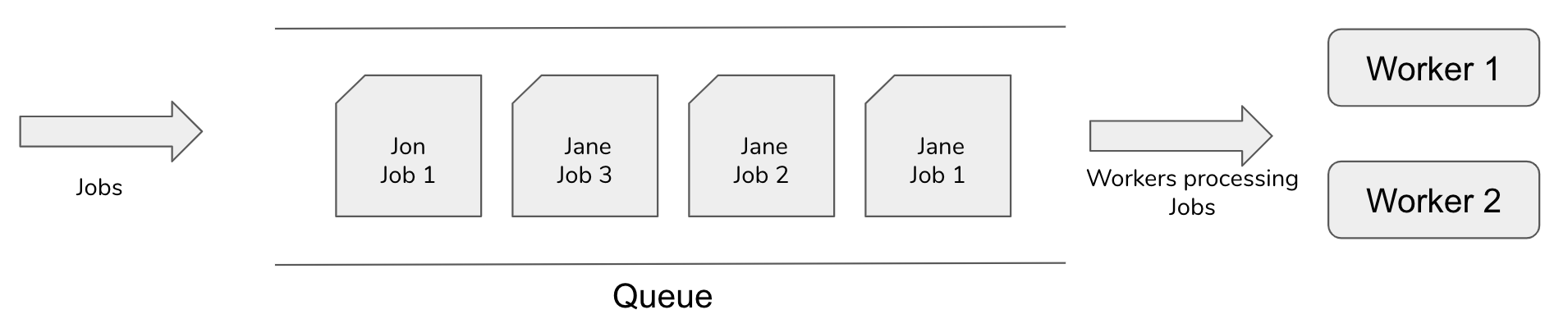
FIFO Job Processing in a Multi-Tenant System
Our first iteration at solving this problem used a randomized algorithm to help ensure each tenant’s next pending job would be equally likely to be selected next. This means if Jane had enqueued 3 jobs right before Jon, Jon and Jane would be treated equally and Jon would not be locked out from running his tasks.
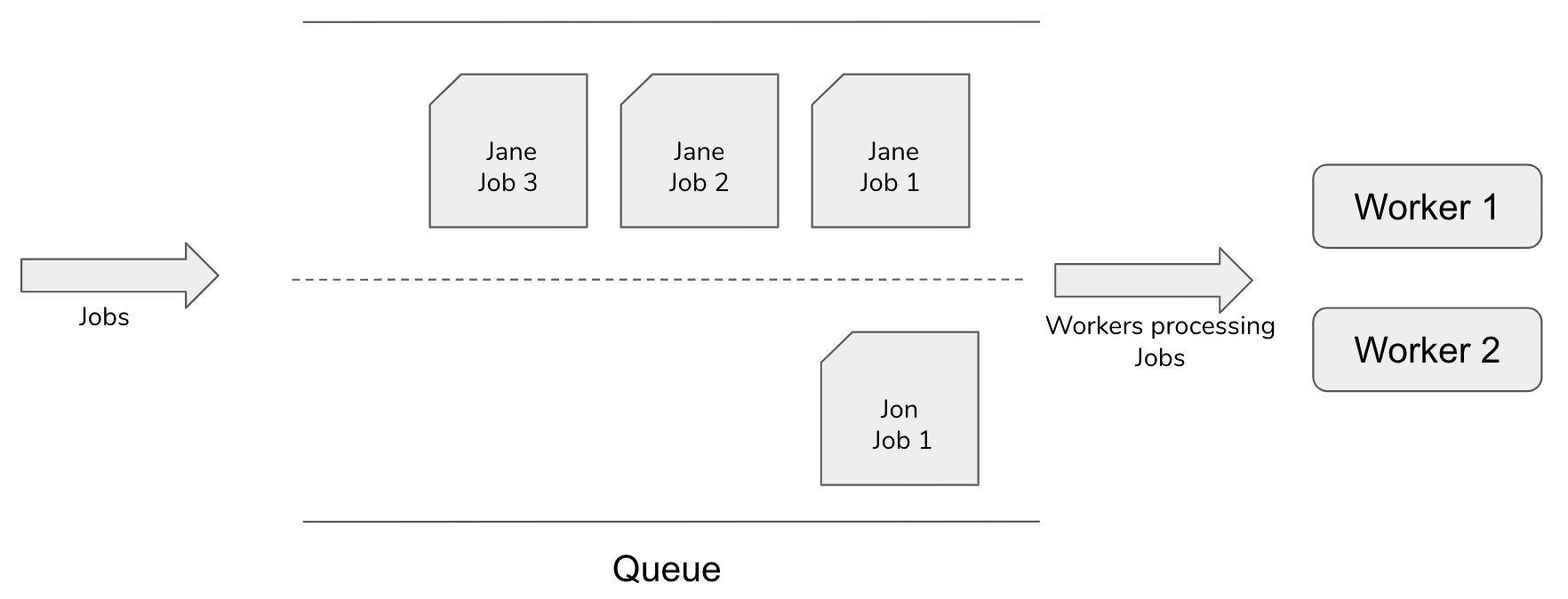 Randomized Job Processing in a Multi-tenant System
Randomized Job Processing in a Multi-tenant System
Whilst a randomized strategy ensures job reservation equality, if a tenant tends to have longer-running jobs, it is likely they will eventually lock up most, if not all of the available workers. There is also a non-zero chance that a tenant will be selected repeatedly at the expense of other tenants. To address this, we added tenant limits to ensure that the total number of jobs a tenant could run simultaneously was bounded. While all these changes greatly improved fairness and user-perceived latency, it introduced several challenges to how much we can scale our job system.
Customizations to how our Delayed Job setup reserved jobs required implementing load balancing algorithms in SQL. The more complicated an algorithm, the more challenging it becomes to implement, test, optimize and scale. As Salsify grew; taking on more and larger customers, the number of jobs we process daily increased to several hundreds of thousands. Our job selection query slowed to an average of 600ms. When under significant load, reserving jobs on high throughput queues could take as long as 4s. In comparison, the mean job duration was 3.8s. Reserving jobs contributed 50% to 80% of our database CPU load; which often hovered between 60% and 90%. Our ability to use Delayed Job to provide our customers with a better platform experience was now limited.
Alternative Options
Other job systems have solved the slow-query problem by using non-relational data stores. For example, Resque uses Redis. Upon analysis, we realized we could also use Redis' robust data structures to model our algorithm in a simple and extensible way. We couldn't completely switch to an out of the box solution like Resque because doing so meant we would have to implement our algorithm by patching Resque's internals. In addition, Our entire platform was built around Delayed Job and its consistency guarantees. For example, a common pattern in Salsify involves creating a database record for a business workflow and enqueuing jobs to run it. A user importing data into the platform will create a database record to track the import and enqueue a job that kicks off all required processing.
Without transactions, users could end up with randomly orphaned workflows which would be a terrible user experience. Over the years we had also developed numerous mission-critical Delayed Job-specific extensions such as the Job Groups, Worker pool, Chainable Hooks and HeartBeat plugins that rely on the same consistency guarantees. For example, the Job Groups plugin relies on transactions to ensure that sets of jobs are orchestrated in a fail-safe manner. Changing this would have been a risky heavy lift.
Our Current Solution
During our summer 2018 hackathon, we prototyped a job system that uses Postgres as the source of truth and Redis for job orchestration with promising results. Running a rudimentary benchmark with our existing system using 200,000 simple no-op jobs evenly distributed across 200 tenants and 6 workers on a Macbook Pro pinned database CPU usage at 100% and saw a job throughput of 15 jobs/s. In comparison, running 395 workers using our prototype led to 50% database CPU usage and a job throughput of 2,700 jobs/s. This benchmark served as a great illustration of the overhead penalty we incurred by solely using the database to drive Delayed Job. We chose Redis because of its robust data structures and atomic scripting support that simplify modeling complex thread-safe algorithms. This idea culminated in the Job Pump; a high-throughput job system that made reserving jobs using our complex fairness strategy inexpensive and fast.
How it Works
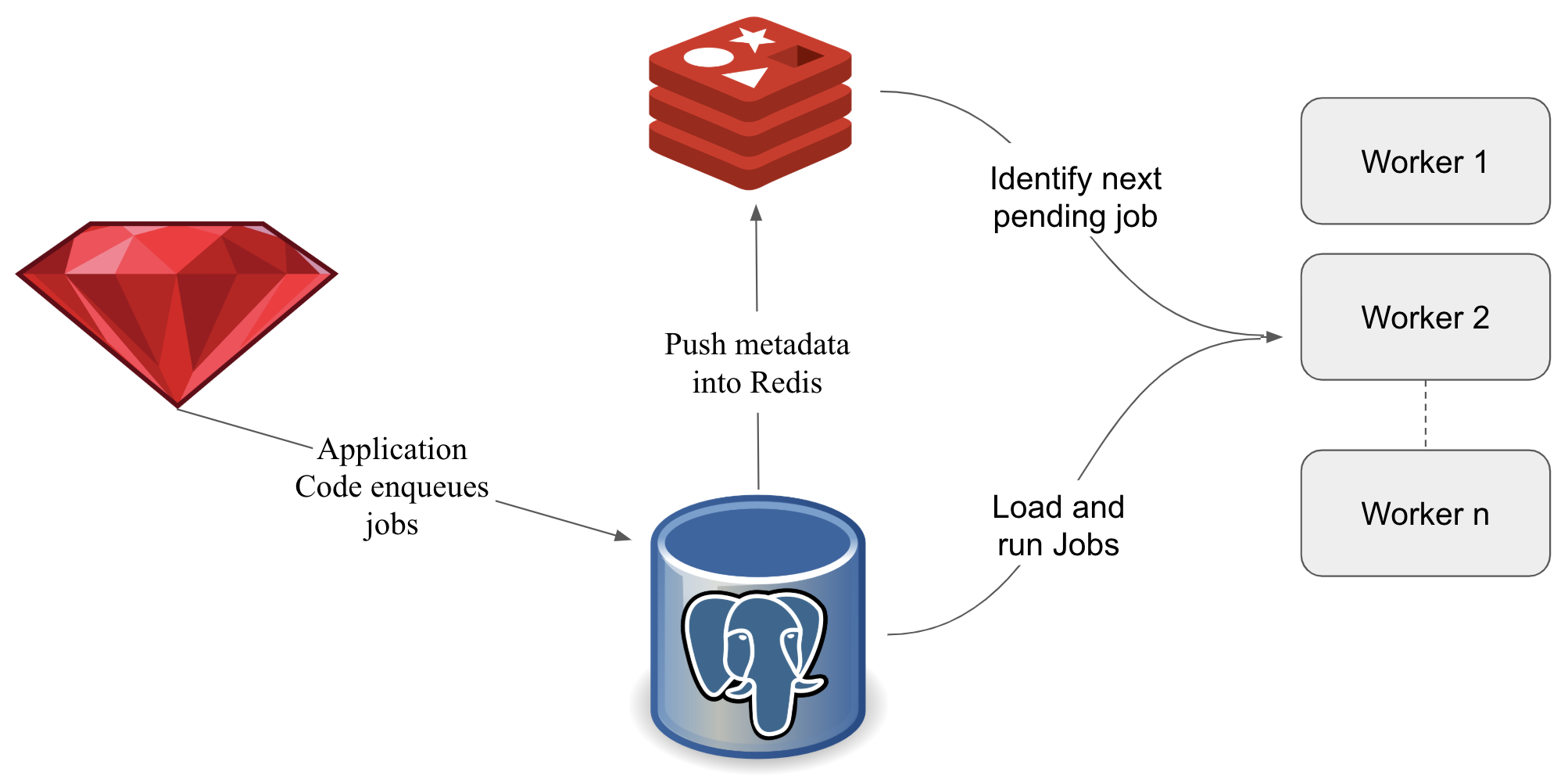
Simplified Representation of the Job Pump
The Job Pump is comprised of a pump and worker processes as well as a fair amount of Lua scripting. Once application code writes new jobs to the database, the pump process pushes the minimal set of job metadata required for orchestration into Redis. The following code snippet shows a simplified version of this.
The worker process is similar to the default Delayed Job process, although it sources jobs differently. Instead of directly querying the database, it polls Redis for the next job to run before loading and running it from Postgres. Once a job succeeds or fails it is marked as such in the database and Redis.
Since our job system runs hundreds of workers, data manipulations in Redis need to be atomic. Redis allows doing so using Lua; a low-level C-like scripting language. This Article covers the mechanics of how that works in greater detail. We made use of this and implemented our fairness algorithm as Lua scripts that are invoked by workers on reserving, rescheduling and completing jobs. Each script atomically manipulates Redis structures in a way that ensures each tenant is equally likely to be selected next without exceeding set limits. We use the following Redis structures:
| Key | Purpose |
| jobs:<job_id> | A hash containing job metadata used to dynamically discover all other data structures relevant to a job. |
| <queue>_pending_jobs:<tenant_id> | A List of pending job ids for a given tenant and queue. |
| tenant_limits | A mapping of queue to the max number of jobs a tenant is allowed to run concurrently. |
| <queue>_running_jobs:<tenant_id> | A set containing ids for all jobs a tenant is currently running for a given queue. |
| <queue>_runnable_tenants | A set containing ids for all tenants who have pending jobs and haven't reached their capacity. |
The publish script initializes a job's metadata in Redis. The reserve script uses what's known about tenants and their pending jobs to identify a job to run. The reschedule script makes a job re-runnable and the remove script removes a job from Redis. Thanks to some meta-programming magic, our workers can invoke each script as a ruby function through the redis_script_runner.
Reliability
The most challenging aspect of this project was ensuring fault tolerance given Redis had become a new mission-critical piece of our infrastructure. For example, our Redis deployment uses asynchronous master-slave replication with 1-second interval disk persistence. If we lost Redis in a disaster scenario, we could lose a few seconds of data. Our Job system needed to be able to re-publish any dropped writes and be eventually consistent. To achieve this, all Lua scripts had to be idempotent. The publish script, for example, checks if a job is already present in Redis before populating any Redis structures. Additionally, processes had to be able to detect recovery scenarios and automatically trigger a republish. Lastly, there are no distributed transactions between Postgres and Redis which further solidifies the need for Redis to be eventually consistent. Solving for this alone is worthy of a blog post.
The Results
Extending Delayed Job this way allowed us to eliminate our most costly database operation. Identifying a job to run became 99.97% faster and database CPU usage fell by 65%. Job throughput increased by 20.18% for a set worker count. This was due to the reduced overhead involved in reserving and completing jobs. Since making these changes, we’ve been able to run significantly more workers using the same hardware which resulted in user-noticeable latency improvements. Our core repository service along with two other high-throughput services are already using our new job system with similar results.
What's next?
In addition to these performance gains, changing our tenant-fairness algorithms has become incredibly simpler. We plan on adding tenant-specific limits as an enhancement to our current queue-specific limits. This will allow us to provision more workers to paying customers than non-paying trial customers. Larger customers would also be able to request more workers to run more concurrent tasks. We are also planning on adding queue pre-empting by introducing bursting. This will involve temporarily allowing tenants to exceed their limits when few other tenants have pending tasks.
Have you had to solve similar job-system scaling problems? Would this be a tool you would love to see open sourced? We’d like to hear about it.